Spark SQL - Join 방식
BroadcastHashJoin / BroadcastNestedJoin
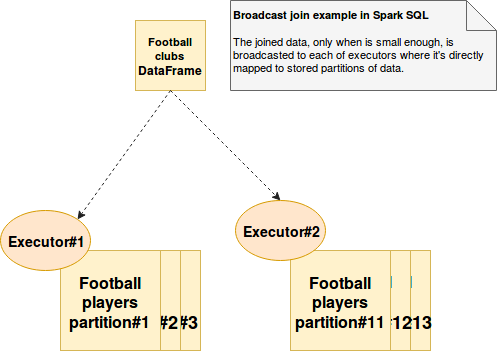
- join을 하는 대상에 전체데이터를 Broadcast해서 사용하는 join 방식
- `spark.sql.autoBroadcastJoinThreshold` 설정으로 Threshold를 조절할수 있다.
- Data가 너무 크게 되면 OOM 에러가 발생이 될수가 있다.
- broadcast를 이용하여 hint를 줄수가 있다.
- 작은 데이터와 큰 데이터를 join을 할때 작은 데이터를 broadcast를 이용하여 성능을 높일수가 있다.
(shuffle을 줄이는 효과)
SortMergeJoin
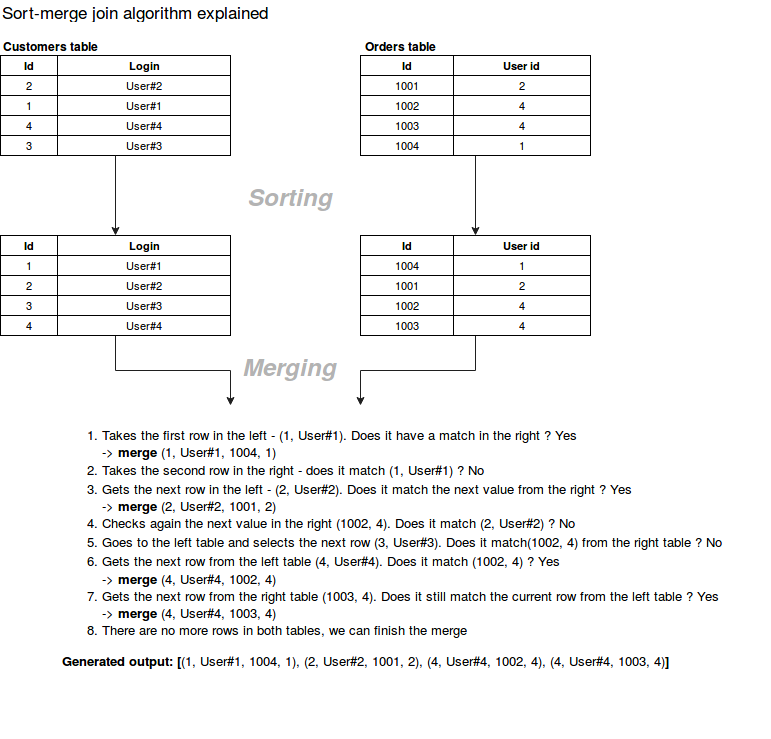
- join을 하는 2개의 데이터셋에 대해 먼저 sort를 진행을 한뒤 join을 하는 방식
- `spark.sql.join.preferSortMergeJoin`를 통해 설정을 할수가 있다.
Shuffle Join
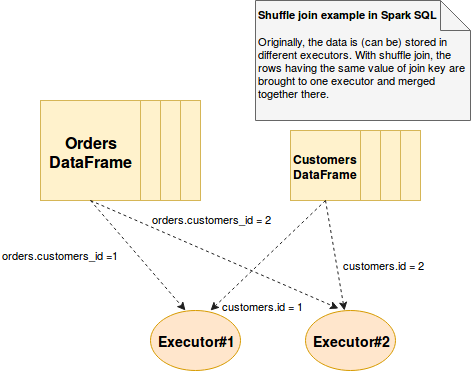
- 같은 키를 가진 date를 같은 executor를 보내 join을 하는 방식
Cartesian Product
- 곱집합
'빅데이터 처리 > Spark' 카테고리의 다른 글
| Spark SQL join, group by and functions (0) | 2019.01.08 |
|---|---|
| Spark 간단하게 하나의 파일로 Write하는 법 (1) | 2019.01.07 |
| Spark AWS S3 접근시 400 에러 처리 방법 (0) | 2019.01.07 |
| Spark SQL, DataFrames, Datasets (0) | 2019.01.05 |
| Spark Word Count Example (0) | 2017.08.07 |