Table of Content
- Table of Content
- RDD (Resilient Distributed Datasets)
RDD (Resilient Distributed Datasets)
Spark = RDD + Interface
Spark의 꽃이라고 할수 있는 RDD에 대해서 알아보자
HDFS
분산 데이터 처리를 위해서 데이터를 저장하기 위한 파일 시스템
Read

Write

MapReduce
맵리듀스(MapReduce)는 구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 제작하여 2004년 발표한 소프트웨어 프레임워크다. 이 프레임워크는 페타바이트 이상의 대용량 데이터를 신뢰도가 낮은 컴퓨터로 구성된 클러스터 환경에서 병렬 처리를 지원하기 위해서 개발되었다. 이 프레임워크는 함수형 프로그래밍에서 일반적으로 사용되는 Map과 Reduce라는 함수 기반으로 주로 구성된다.
Map
다수 프로그래밍 언어에서, map은 고차 함수로서 전해진 함수를 배열의 모든 요소에 적용(apply)하여 그 결과 배열을 전달한다.
예를 들어 만약 다음과 같은 함수를 정의할 때,
square x = x * x
그 뒤 map square [1,2,3,4,5] 라고 호출한다면 해당 명령은 [1,4,9,16,25]를 반환하는데, 이 때 map은 배열을 지나면서 모든 요소에 대해 square 함수를 적용한다.
Reduce
함수형 프로그래밍에서 fold란 고차 함수의 계열 중 하나이다. reduce, accumulate, compress 혹은 inject 등 다양하게 알려져 있다. 재귀적인 자료 구조를 분석하고, 전달받은 결합된 명령들을 사용하여 재결합하며, 재귀적으로 수행된 그 결과들로 반환 값(return value)을 만들어낸다. 보통 fold는 함수를 자료 구조의 최상위 노드의 조합 함수의 형태로 표현되며, 특정 조건 하에서 사용할 수 있는 어떤 기본 값(default values)을 가질 수 있다. 그리고 계통적인 방식으로 그 함수를 사용하여 자료 구조의 위계 상의 요소들을 조합하는 과정을 진행한다.
대형 데이터 분석에 쉽게 만들어 주긴 했으나, 더 복잡하고 Multi-Stage(머신러닝, 그래프)와 같은 작업을 하기에는 속도가 느리다. MapReduce가 느린이유는 HDFS에 저장을 하기 때문에, 즉 데이터의 중간 과정을 DISK에 저장하기 때문에 느리지게 된다.
RDD (Resilient Distributed Datasets)
HDFS에 저장하여 처리하는 MapReduce와 다르게 메모리에 저장을 하고 처리를 하면 속도가 빠르다는 것을 착안해서 나온 데이터셋이다. 하지만 메모리의 특성상 중간에 오류(Fault)가 나면 모든 데이터가 사라지게 된다. 이를 해결하기 위해 Fault-tolerant & efficient 하게 만든 데이터 구조를 RDD라고 한다. HDFS는 수정(Modify)이 되지 않는 시스템와 동일하게 RDD도 수정(Modifiy)이 되지 않는 데이터 구조 (Read-Only) 이다.
특성
- Immutable, Read-only
- Datasource -> RDD, RDD -> RDD로만 변경이 가능함.
- 부모로부터 어떻게 만들어지는지 계보(리니지, lineage)을 기록을 통해 fault-tolerant
- 계보는 어디에 저장을 할까?
- RDD가 살아있는 driver에 RDD lineage가 존재한다.
- 계보는 어디에 저장을 할까?
- 자료가 어떻게 변해 갈지 (Transformation)에서는 실제 계산이 되지 않는다.
Transformation
- map, reduce, join 등 단순히 map, reduce만 쓰던 MR 보다 명령어가 풍부하다.
Lazy-Execution
- action이 실행되기전까지는 실행이 되지 않는다.
- 자원이 배치된 배치될 상황을 미리 고려하여 최적의 코스를 돌 수 있다.
RDD 시작하기
- 언어는 Java/Scala/Python 등을 사용할수 있으나 Java 기준으로 설명한다.
Spark Context 시작하기
- Spark를 사용할려면 SparkContext 객체를 반드시 생성을 해야 된다.
;;
파라미터 설명
- appName : cluster UI에서 보이는 Application Name
- master : spark, mesos, yarn cluster url, local mode
Spark Shell로 이용하는 방법
./bin/spark-shell --master local
- scala 언어만 가능하다.
Collection 객체를 이용하여 RDD 생성하는 방법
;;
- 자원에 따라 partition이 나눠어 진다. 보통 cluster의 cpu 갯수당 2-4개 정도로 나누워 진다.
- 파라미터를 통해 partition 갯수를 정할수가 있다.
sc.parallelize(data, 10)
파일로 부터 RDD 생성하는 방법
;
- 만약 local system에 존재하는 파일을 사용할 경우에는 각각의 worker 들에게 데이터를 복사해주거나, NFS(network-mounted shared file system)를 사용한다.
- 압축파일, Wildcard, 폴더 등도 지원을 한다.
- textFile 매서드 동일하게 파라미터를 통해 partition 갯수를 정할수가 있다. (HDFS일경우에는 기본적으로 128MB씩 분리)
wholeTextFiles를 사용한다면 전체 데이터를 한꺼번에 읽을수가 있다.
읽어 올수 있는 데이터 저장소
- Local File
- HDFS
- Amazon S3
s3n://.... - SequenceFile (Hadoop)
- Any Hadoop Input File 등..
RDD Operation
- Transformation : 기존의 데이터(RDD)로부터 새로운 데이터(RDD) 만드는 기능
- 모든 Transformation 과정은 lazy하게 진행하게 된다. 좀더 효율적인 방법으로 계산이 되도록 한다.
- Action : 계산된 값을 얻어오는 기능
- 기본 설정으로는 Transformation된 RDD는 다시 실행할때마다 다시 계산(compute)가 될것이다. 다음음에 좀더 빠른 Query 성능을 위해서 Persist(또는 cache)를 이용하여 RDD를 저장을 할수가 있다.
Basic
;;;
lineLengths;
- lineLengths는 일단 한번 계산된후 Memory에 저장을 한다.
Spark에 함수로 전달로하기
org.apache.spark.api.java.function인터페이스를 구현하면 된다.
;;;
또는
}};;;
클로저(Closures) 이해
클로저란?
(Lexical) Closure. 클로저는 함수가 선언될 당시의 환경(environment) 을 기억했다가 나중에 호출되었을때 원래의 환경에 따라 수행되는 함수이다. 이름이 클로져인 이유는 함수 선언 시의 scope(lexical scope)를 포섭(closure)하여 실행될 때 이용하기 때문이다. 자주 '이름 없는 함수(익명함수)'와 혼동되곤 한다. 많은 언어의 익명함수가 closure를 포함하기 때문에 편하게 부를땐 서로 구분없이 부르기도 한다.
현장에서 클로저가 자주 쓰이는 언어로는 JavaScript가 유명하다.
{return {// a는 당시의 환경, 이를 기억함.return a + x;}}var plus3 = ;var plus5 = ;
Example
;;// Wrong: Don't do this!! 이렇게 쓰지마rdd;;
- 환경에 따라 다른 값이 나올수가 있다. (다른 cluster node 혹은 jvm 등등으로 인해)
Local vs Cluster 모드
위와 같은 코드는 어떻게 실행되는지는 알수가 없다.
RDD 값 출력
하나의 컴퓨터 (Single Machine)일 경우에는 기대한대로 RDD의 값들을 출력을 할수가 있다. 하지만 Cluster 모드에서는 Executor의 stdout를 사용하기 때문에 driver에 출력이 되는 것이 아니라 각각의 cluster node에 출력이 된다.collect 매서드를 사용한다면 driver node로 데이터를 가지고 와서 출력을 할수 있으나 OOM(Out ouf Memory)가 발생될 가능성이 높다. collect는 전체 RDD 데이터를 Single Machine으로 전부 가지고 오기 때문이다.collect 보다는 take를 이용해서 몇개의 데이터만 가지고 오는 것이 훨씬 낫다.rdd.take(100).foreach(println)
Key-Value Pair Operation
- 특정 Operation는 Key-Value 객체를 처리하는 곳에 이용된다.
- Scala인 경우에는
scala.Tuple2 - Java인 경우에는
JavaPairRDD클래스를 사용하면 된다.
;;;
- Note : Key-Value Operation를 사용하기 위해서는
Object.equals()와Object.hashcode()의 정의가 필요하다
Transform RDD
| Transformation | 의미 |
|---|---|
| map(func) | 새로운 타입의 RDD를 결과값을 얻는다. |
| filter(func) | 조건에 필터된 RDD를 얻는다. |
| flatMap(func) | map와 비슷하지만 input값이 0개로 맵핑 될수도 있고 n개로 맵핑이 될수가 있다. |
| mapPartitions(func) | map(func)와 비슷하지만 partition 단위 map 연산을 한다. 따라서 Iterator 객가 input/ouput값이다. (Iterator<T>)=>Iterator<U> |
| mapPartitionsWithIndex(func) | mapPartitions가 동일하나 index가 존재한다 (i, Iterator<T>)=>Iterator<U> |
| sample(withReplacement, fraction, seed) | 샘플링된 RDD로 리턴한다. |
| union(otherDataset) | 다른 RDD와 합쳐진 결과값을 리턴한다. |
| intersection(otherDataset) | 2개의 RDD에서 서로 교차 되어 있는 (intersection) 값 리턴한다. |
| distinct([numTasks])) | 중복된 값 제거, SQL distinct와 유사하다. |
| groupByKey([numTasks]) | (K, V) Pair 객체를 이용하여 (K, Iterator<V>) 만들어 준다. sql의 group by 기능과 동일하다. |
| reduceByKey(func, [numTasks]) | (K, V) Pair 객체에서 Key 기준으로 reduce 할때 사용한다. |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | (K,V) 객체에서 (K, U) 객체로 aggregate |
| sortByKey([ascending], [numTasks]) | Key 값을 기준으로 sort (desc, asc) |
| join(otherDataset, [numTasks]) | (K, V) RDD와 (K, U) RDD을 join (K, (V, U)) 값을 리턴한다. |
| cogroup(otherDataset, [numTasks]) | (K, V) RDD와 (K,U) RDD를 join (K (Iterator <V>, Iterator<U>)) |
| pipe(command, [envVars]) | shell command를 통해 rdd를 생성할 수 있다. shell command의 pipe 기능과 유사 (>, >>, >>>) |
| coalesce(numPartitions) | partition 갯수를 줄인다. |
| repartition(numPartitions) | partition을 다시 shuffle 한다. partition의 갯수를 늘리거나 줄일수가 있다. |
| repartitionAndSortWithinPartitions(partitioner) | RDD의 partition를 다시 진행한다. 각각의 partion은 sort가 된 값들이 존재한다. |
Action RDD
| Action | 의미 |
|---|---|
| reduce(func) | 데이터셋의 데이터를 하나로 만들어 준다(aggregate) |
| collect() | 모든 RDD를 driver 프로그램에 array 형태로 리턴한다. |
| count() | 데이터의 갯수를 리턴한다. |
| first() | 첫번재 데이터를 가지고 온다. |
| take(n) | n개의 데이터를 가지고 온다. |
| takeSample(withReplacement, num, [seed]) | num 갯수의 데이터를 샘플링한다. |
| takeOrdered(n, [ordering]) | sort된 데이터 중에 n개를 가지고 온다. |
| saveAsTextFile(path) | 데이터를 파일로 저장한다. |
| saveAsSequenceFile(path) | 데이터를 SequenceFile로 저장한다. |
| saveAsObjectFile(path) | 데이터를 ObjectFile로 저장한다. |
| countByKey() | (K,V) Pair 객체일때만 사용이 가능한다. 각각의 key에 대해 갯수를 센다 (K, int) |
| foreach(func) | 각각의 데이터에 대해 함수를 실행시킨다 (for-문) |
- 또한 Action API로써
foreachAsync같이 Async 기능으로써도 활용이 가능하다.FutureAction를 리턴함으로써 action에 대해 비동기적으로 처리가 가능하다.
Shuffle Operation
특정 기능은 셔플(Shuffle)와 함께 실행되는 것들이 존재한다. 셔플(Shuffle)이란 스파크에서 데이터를 다시 재분배하는 방법이다.
Background
셔플을 이해하기 위해서는 reduceByKey의 작동 방식을 알면 된다. reduceByKey는 하나의 key에 연결된 tuple 데이터를 합치기 위해 모든 데이터를 가지고 와야 된다. 문제는 모든 데이터가 한 partition이나 한 컴퓨터에 있다는 보장이 없다. 그래서 데이터의 위치를 재 조정되고 작업을 시작하게 된다.
- repartition operations (repartition, coalesce)
- ByKey operations (groupByKey, reduceByKey)
- join operations (cogroup, join)
성능적인 이슈
셔플 (Shuffle)은 disk I/O, data serialization, and network I/O를 포함하고 있기 때문에 비싼 연산에 속한다. Shuffle은 Shuffle Behavior 설정을 통해 튜닝을 할수 있다. Spark Configuration Guide
RDD Persistence
Spark에서 중요한 기능중에 하나로 데이터셋를 저장하는 기능이다. persist() 또는 cache() 매서드를 이용하여 사용할수 있다. 데이터셋을 저장을 할때 StorageLevel 를 설정하여 저장하는 위치를 정할수가 있다. cache()인 경우에는 StorageLevel.MEMORY_ONLY로 정해져 있다.
| Storage Level | 의미 |
|---|---|
| MEMORY_ONLY | JVM에 자바 객체(deserialized)를 메모리에서만 저장, 메모리가 부족하다면 저장되지 않는다. 만약 다시 필요하다면 다시 계산을 한다. |
| MEMORY_AND_DISK | JVM에서 자바 객체(deserialized)를 메모리에서 저장, 메모리가 부족하다면 디스크에 저장한다. 용량도 부족하다 |
| MEMORY_ONLY_SER (Java and Scala) | 자바 객체 (serialized) 객체를 메모리에서만 저장, fast serialization library사용을 할수가 있으나 이럴 경우에는 cpu 사용량이 높아진다. |
| MEMORY_AND_DISK_SER (Java and Scala) | 자바 객체 (serialized) 객체를 메모리, 디스크에 저장 |
| DISK_ONLY | DISK에서만 저장을 한다. |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | 다른 기능들과 동일하나, 2개의 cluster node에 대해 복제 (replicated) 저장을 한다. |
| OFF_HEAP (experimental) | MEMORY_ONLY_SER 비슷하나 off-heap memory에 저장이 된다. |
- Python이 인경우에는 Pickle를 통해 항상 직렬화를 하기 때문에 serialized level이 존재하지 않는다.
- Shuffle이 일어나는 groupByKey와 같은 operation 전에 사용을 한다면 Shuffle 중에 오류가 발생되었을때 빨리 복구가 가능하다.
어떤 StorageLevel를 선택을 해야 될까?
- 데이터의 크기가 적당하다면 기본 설정 (MEMORY_ONLY) 을 사용한다. 이 설정이 cpu 사용이 가장 효율적이다.
- MEMORY_ONLY_SER를 사용하고, fast serialization library를 선택을 했다면 공간 효율적으로 사용이 가능하다. 접근할때 속도가 꽤 빠르다.
- disk에 넘치지 않지만, 데이터의 크기가 많이 크다면 DISK에 저장을 하여 사용한다.
- 빠른 오류 복구가 필요하다면 MEMORY_ONLY_2, MEMORY_AND_DISK_2를 사용한다.
저장된 데이터는 언제 지워질까?
Spark 자체에서 모니터링을 통해 LRU 방식으로 데이터를 지운다. 직접 지울려고 할려면 RDD.unpersist()매서드를 호출을 한다.
Shared Variables
spark는 모든 cluster node에서 사용될수 있는 shared variables 를 제공한다.
Broadcast Variables
;broadcastVar;// returns [1, 2, 3]
- 모든 노드에서 동일한 값을 보장하기 위해 한번 생성된 이유로 수정이 되지 않는다. (Read-Only)
Accumulators
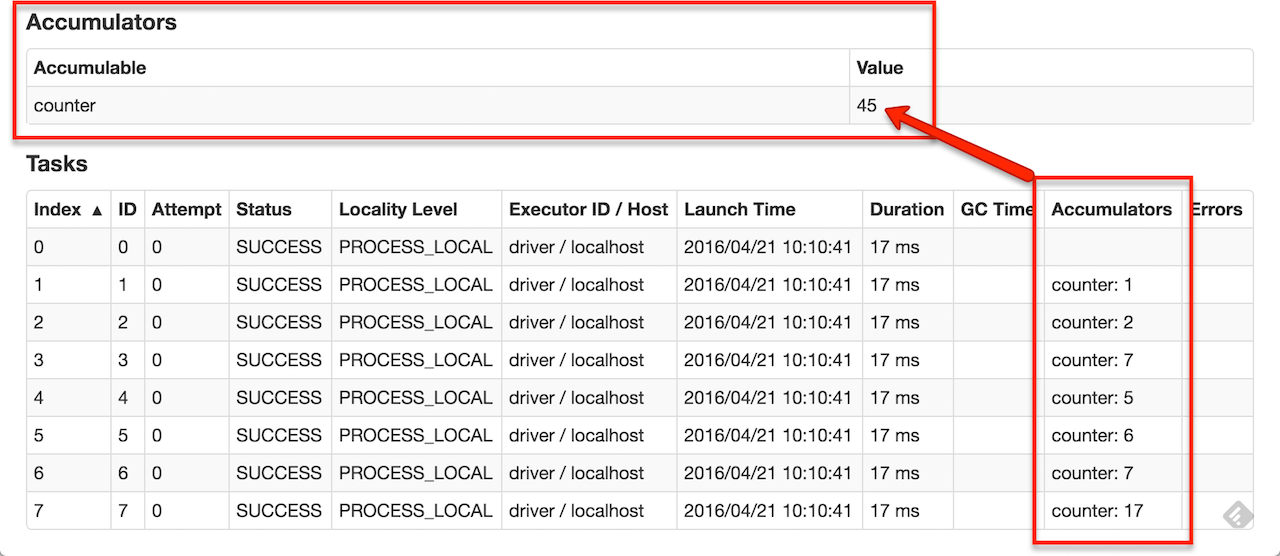
;sc;// ...// 10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 saccum;// returns 10
Reference
'빅데이터 처리 > Spark' 카테고리의 다른 글
| Spark SQL join, group by and functions (0) | 2019.01.08 |
|---|---|
| Spark 간단하게 하나의 파일로 Write하는 법 (1) | 2019.01.07 |
| Spark AWS S3 접근시 400 에러 처리 방법 (0) | 2019.01.07 |
| Spark SQL, DataFrames, Datasets (0) | 2019.01.05 |
| Spark Word Count Example (0) | 2017.08.07 |